当你着手使用关系型数据库设计一个新的基于数据驱动的应用程序时,你可能首先根据一系列属性的领域模型创建标准化的表,并使用外键将关联的数据指向其他表。
下面的图展示了你如何使用关系型数据库模型代表在应用程序中的数据存储。相关的模型包含若干个“join”为了实现多到多的关系,包括酒店对应兴趣点,房间对用设施,房间对应是否被占用,房间对应客人。
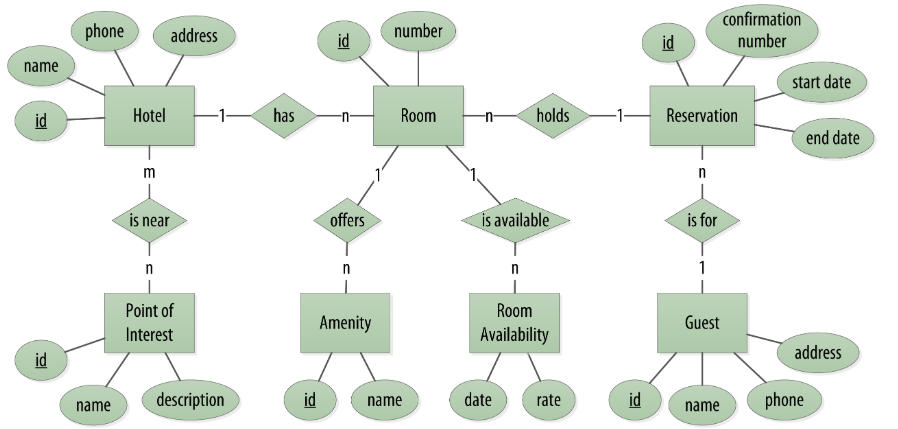
RDBMS和Cassandra设计上的不同
我们来花一些时间强调下Cassandra和关系型数据库的差异。
没有join
在Cassandra中不能执行join,如果你设计了一个数据模型,并且要使用join查询,你需要在客户端处理或者创建一个非标准化的表来存储join的结果。后者是Cassandra的优选,在客户端执行join应该是较为特殊的操作。应该替换为冗余数据。
- 没有完整指向
尽管Cassandra支持一些轻量级事务和批量操作的特性,但没有跨表完整性的概念。在关系型数据库中,你可以在表中指定外键(foreign keys)指向另外一张表的主键,但Cassandra没有这个。在表中通过存储id关联别的实体仍然是个通用设计要求,但比如级联删除这些操作不可用。
- 非范式
在关系型数据库设计中,经常会告诉你标准化的重要性。在Cassandra中这不是优势,因为在非标准化的场景下它做的更好。有以下两点,一是性能,当需要对多年有价值的数据建立很多join的时候,公司不能简便的提升性能,因此最后的工作应该进行查询非规范化改造。但有违关系数据库的设计。最终使人质疑使用关系数据库在这种情况下是否是最好的方法。
第二个原因是关系型数据库非规范化设计是业务文档结果需要保留。即需要一个封闭的表来查询大量外部表数据可能随时间变化而变化。你需要保持一个封闭文档作为历史版本的快照。常见的例子是发票,你需要创建顾客表和产品表,并且要考虑发票指向这些表。但实际上是做不到的,顾客或者价格信息时刻在发生着变化。你将失去发票文档在发票日期上的完整性,这可能违反审核、报告或法律,并导致其他问题。
在关系世界中,非范式违反了Codd范式,因此你会尽力避免这么做。但是在Cassandra中,反范式设计是很正常的,如果你的数据模型非常简单则不是必须的。不要害怕他。
在过去,Cassandra中非范式是必须的并且使用本文档中描述的技术管理多个表,但从3.0开始,Cassandra提供了一个称为物化视图的特性允许基于一个基本表创建多个非范式数据视图。Cassandra在服务端管理物化视图,包括保持视图同步表的工作。
查询优先设计
简单来说,关系建模意味着您从概念领域开始,然后在表中表示领域中的名词。然后分配主键和外键来建立模型关系。当具有多对多关系时,将创建仅代表那些键的联接表。联接表在现实世界中不存在,并且是关系模型工作方式的必要副作用。布置完所有表后,可以开始编写查询,这些查询使用键定义的关系将不同的数据汇总在一起。关系世界中的查询非常次要。假定只要表已正确建模,就可以始终获取所需的数据。即使必须使用多个复杂的子查询或join语句,通常也是如此。
相比之下,在Cassandra中不是从数据模型开始的。而是从查询模型开始。不用先对数据建模然后编写查询,而是使用Cassandra对查询进行建模并让数据围绕它们进行组织。考虑一下应用程序使用的最常见查询路径,然后创建支持它们的表。
批评者认为,先设计查询会过度限制应用程序设计,更不用说数据库建模了。但是,完全可以合理地期望您应该认真考虑应用程序中的查询,就像你可能认真思考关系域一样。你可能会弄错它,然后在任何地方都会遇到问题。否则你的查询需求可能会随着时间而变化,那么将不得不努力更新数据集。但这与在RDBMS中定义错误的表或需要其他表没有什么不同。
最佳存储设计
在关系型数据库中,表怎么存储在硬盘上对用户来说通常是透明的,并且很少听到关于RDBMS关于表存储数据模型的意见。然而,在Cassandra中这是非常重要的考虑因素。这是因为Cassandra的表存储在独立的文件中和保持有关联的列定义在同一张表中很重要。
排序设计决策
在RDBMS中,在查询中,你能很轻易的通过ORDER BY对返回的结果进行排序,默认的排序规则是不能配置的,默认情况下,通过顺序写返回记录,如果要改变顺序,那么需要修改查询和通过列进行排序。
然而,在Cassandra中,排序要差异化处理。这样设计的原因是:查询上的排序顺序是固定的,和完全取决于供应在CREATE TABLE命令上集群列的选择.CQLSELECT语句不支持ORDER BY语义,仅支持通过集群列进行排序。
写在最后
该文基于官方翻译,本人水平有限,如有不当,敬请指出。查看原文